
nov 16, 2020
Para um atendimento médico justo e igualitário, precisamos de uma IA justa e livre de preconceitos
A inteligência artificial (IA) tem o potencial de tornar o atendimento médico mais acessível e eficaz, com preços também acessíveis, mas pode também, inadvertidamente, levar a conclusões errôneas e, com isso, amplificar as desigualdades existentes. Atenuar esses riscos requer estar consciente de que um preconceito pode se infiltrar nos algoritmos de IA e saber como evitar que isso aconteça por meio de um design e implementação cuidadosos. Em um estudo amplamente divulgado publicado na Science no ano passado, um grupo de pesquisadores da Universidade da Califórnia revelou que um algoritmo usado por hospitais dos EUA para sinalizar pacientes de alto risco e obter maior atenção dos médicos exibia um preconceito racial significativo. Os pacientes negros estavam menos propensos a serem sinalizados para cuidados adicionais do que os pacientes brancos, mesmo quando estavam igualmente doentes [1]. Tecnicamente, não havia nada de errado com o algoritmo e seus criadores nunca tiveram a intenção de fazer com que discriminasse alguém. Na verdade, projetaram o algoritmo para que não considerasse as características raciais. Então, o que fez com que se tornasse preconceituoso? O problema era que, ao identificar pacientes de alto risco que precisavam de cuidados adicionais, o algoritmo estava prevendo custos futuros do atendimento médico, ao invés de doenças futuras. Como os pacientes negros nos EUA tendem, em média, a ter um acesso mais limitado a um atendimento médico de alta qualidade, normalmente incorrem em custos mais baixos do que pacientes brancos com as mesmas condições. Portanto, o fato de se basear nos custos do atendimento como um indicador do risco de doenças e de necessidades médicas coloca os pacientes negros em uma considerável posição de desvantagem. Quando, alternativamente, os pesquisadores fizeram uma simulação com dados clínicos, o percentual de pessoas negras encaminhadas para um atendimento médico adicional aumentou de 17,7 para 46,5% [i]. Esse estudo destaca como as profundas disparidades nos sistemas de saúde podem ser reforçadas involuntariamente por algoritmos de IA. Com um design cuidadoso, a IA promete criar um futuro mais saudável e mais igualitário para todos. Mas há também o risco de acabarmos codificando desigualdades atuais e passadas.
Com um design cuidadoso, a IA promete criar um futuro mais saudável e mais igualitário para todos. Mas há também o risco de acabarmos codificando desigualdades atuais e passadas.
É um risco já bem reconhecido na comunidade médica. De acordo com uma pesquisa recente realizada pela Healthcare Information and Management Systems Society (HIMSS), 93% dos profissionais de saúde e de TI em saúde estão pelo menos um pouco preocupados com a possibilidade de preconceitos existentes serem transferidos para os algoritmos de IA [2].
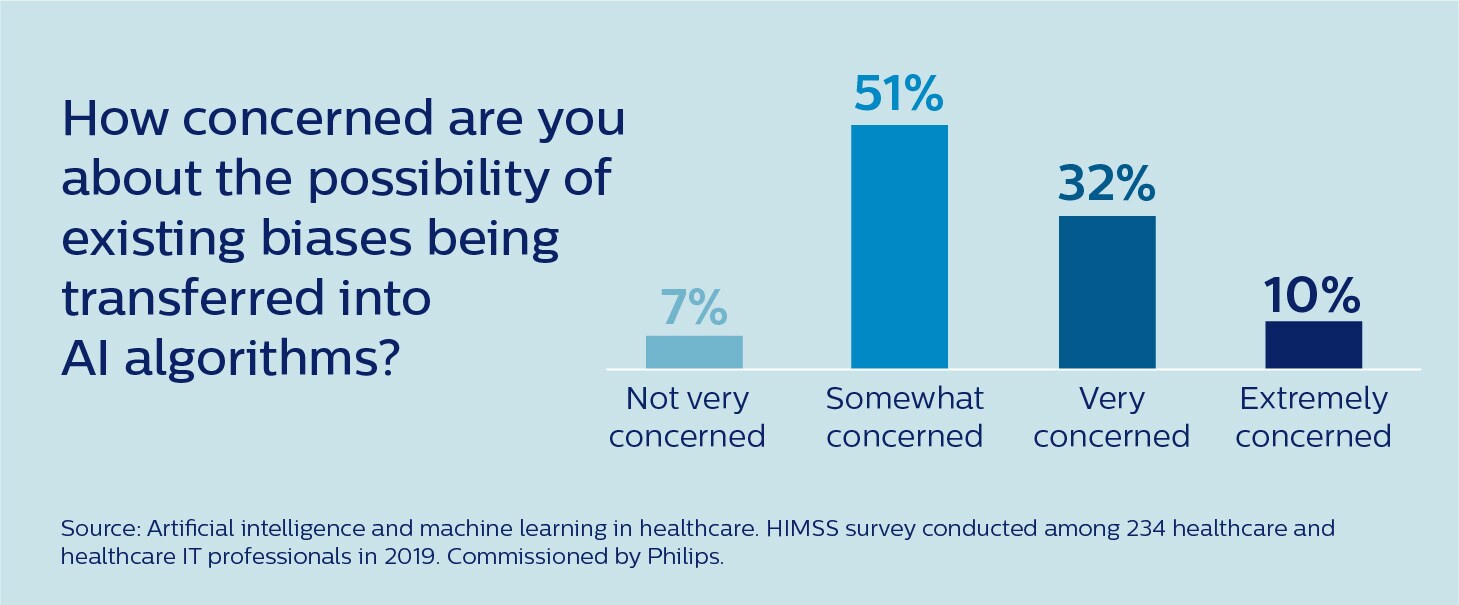
Então, como podemos garantir que a IA seja igualitária e ajude a reduzir as disparidades de saúde existentes ao invés de exacerbá-las?
Como o preconceito pode surgir na IA
Para mitigar efetivamente o risco de preconceito em IA no atendimento médico, devemos primeiro entender as diferentes maneiras pelas quais ele pode surgir. Possivelmente, o maior obstáculo no desenvolvimento e implementação da IA é que aceitamos seus resultados sem espírito crítico, sem submeter suas inserções e o design subjacente a um escrutínio suficiente. É um fenômeno psicológico bem documentado que as pessoas tendem a aceitar sem discutir as recomendações baseadas em computador [3]. Os algoritmos de IA conferem um verniz de objetividade e imparcialidade a qualquer processo de tomada de decisão. A verdade, no entanto, é que a contribuição de um algoritmo é em grande parte definida pelos dados que inserimos nele e por outras preferências dos humanos que orientam o desenvolvimento e a implantação desse algoritmo. Essas preferências podem estar sujeitas a preconceitos que, involuntariamente, colocam certos grupos em posição de desvantagem.
Possivelmente, o maior obstáculo no desenvolvimento e implementação da IA é que aceitamos seus resultados sem espírito crítico, sem submeter suas inserções e o design subjacente a um escrutínio suficiente.
O atendimento médico está sujeito a um alto risco de preconceito que tenta se infiltrar desde o início, no momento em que os dados para treinar um algoritmo são selecionados. Isso ocorre porque os conjuntos de dados disponíveis podem não ser representativos da população visada. Por exemplo, mulheres e negros são sabidamente sub-representados nos estudos clínicos [4,5]. A pesquisa de genômica está muito longe de adotar uma maior inclusividade, com 81% dos participantes sendo de ascendência europeia [6]. Dados tendenciosos implicam o perigo de uma IA tendenciosa. Pesquisadores expressaram suas preocupações no sentido de que os algoritmos que analisam imagens cutâneas poderiam deixar passar melanomas malignos em negros porque os algoritmos são predominantemente treinados em imagens de pacientes brancos [7]. Da mesma forma, alguns têm questionado se os algoritmos projetados para priorizar o atendimento aos pacientes portadores de COVID-19 estão na verdade aumentando o fardo da doença para as populações carentes [8]. Se essas populações não tiverem acesso aos testes de COVID-19, os algoritmos poderão não levar em conta suas necessidades e características porque estão sub-representadas nos dados de treinamento. Escolhas feitas durante o processamento de dados e desenvolvimento de algoritmos também podem contribuir para o preconceito, mesmo que os dados propriamente ditos estejam livres de preconceitos. Por exemplo, diferenças relevantes entre as populações podem ser negligenciadas na busca de um modelo que, em tese, atenda a todos. Sabemos que muitas doenças se apresentam de forma diferente em homens e mulheres, entre elas as doenças cardiovasculares, diabetes ou transtornos de saúde mental como a depressão e o autismo. Ao não levarem essas diferenças em conta, os algoritmos poderiam ampliar as desigualdades de gênero já existentes [9]. Para terminar, é importante entender que o que é justo e inclusivo em determinado contexto pode não sê-lo em outro. Um exemplo revelador é um algoritmo que foi desenvolvido em um hospital de Washington para anotar resultados de exames nos relatórios de pacientes com câncer com base em observações do médico. O algoritmo teve um desempenho muito bom no hospital de Washington. Mas quando foi aplicado em um hospital de Kentucky, seu desempenho despencou. O motivo? Os médicos em Kentucky usavam uma terminologia diferente em suas observações [10]. Resumindo, o preconceito pode ocorrer em qualquer fase do desenvolvimento e implantação de IA, desde o uso de conjuntos de dados tendenciosos até a implantação de algoritmos em um contexto diferente daquele em que foi treinado:
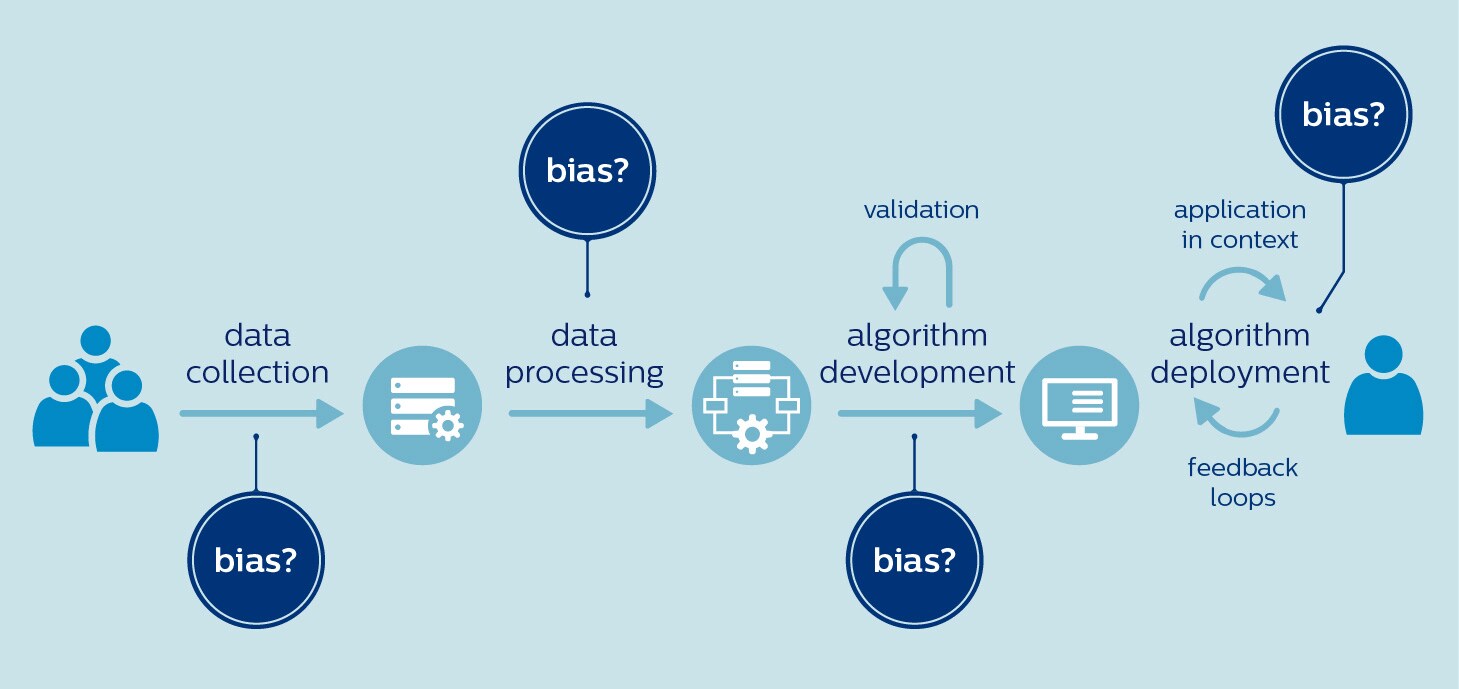
A questão, então, é o que podemos fazer a respeito.
Acolhendo a equidade como um princípio norteador
Os órgãos públicos e reguladores e os players do setor privado já reconheceram a necessidade de políticas e princípios orientadores claros para evitar o preconceito na IA. Em uma tentativa de promover o uso benéfico e responsável da IA, a Comissão Europeia criou um Grupo de Especialistas de Alto Nível (HLEG) que publicou diretrizes sobre o que constitui uma IA confiável, incluindo "diversidade, não discriminação e equidade". Nos EUA, foi proposta a Lei de Responsabilidade Algorítmica, que pretende exigir que as empresas avaliem seus sistemas de IA para detectar riscos de decisões injustas, tendenciosas ou discriminatórias. E na China, a Administração Nacional de Produtos Médicos (NMPA) emitiu recentemente uma nova regulamentação [em chinês] para controlar o risco de preconceito em dispositivos médicos. Na Philips, adotamos a equidade como um dos nossos cinco princípios orientadores do uso responsável da IA. Acreditamos que as soluções habilitadas para IA devem ser desenvolvidas e validadas com dados representativos do grupo visado para o uso pretendido e, ao mesmo tempo, evitar o preconceito e a discriminação.
A equidade deve ser um princípio norteador do uso responsável da IA.
É claro que o valor de qualquer princípio é limitado pelas práticas que o corroboram. Devido ao fato de que muitas possíveis fontes de preconceito estão intrincadas nos dados de saúde da atualidade, refletindo desigualdades históricas e socioeconômicas, nosso setor tem pela frente desafios formidáveis a serem superados. Na verdade, a maioria desses desafios não são específicos da IA e da ciência de dados e exigem mudanças mais amplas e sistêmicas, como, por exemplo, aprimorar o acesso da população carente ao atendimento médico e tornar a pesquisa médica mais inclusiva. No que se refere especificamente à IA e à ciência de dados, é necessária uma maior conscientização sobre a forma como o preconceito pode surgir em vários estágios de desenvolvimento de um algoritmo e como isso pode ser mitigado. A empreitada começa com treinamento e educação. Além disso, precisamos desenvolver sistemas sólidos de gestão de qualidade para monitorar e documentar a finalidade, a qualidade dos dados, o processo de desenvolvimento e o desempenho de um algoritmo. E, talvez mais fundamentalmente, precisamos incorporar a diversidade em todos os aspectos do desenvolvimento da IA.
Três tipos de diversidade que são importantes
Existem três tipos de diversidade que são essenciais para o desenvolvimento de uma IA igualitária: diversidade de pessoas, diversidade de dados e diversidade de validação. A seguir vou elaborar sobre cada um.
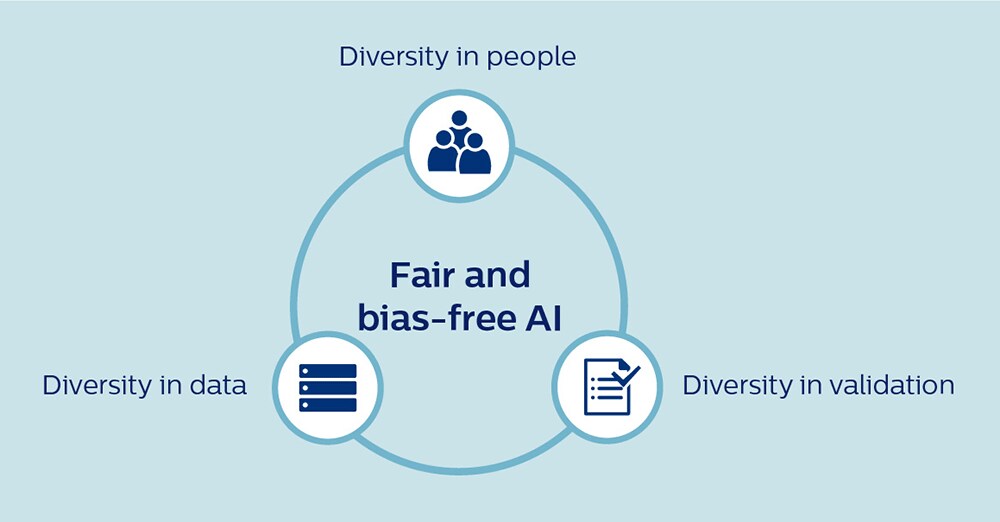
1. Diversidade de pessoas Em primeiro lugar, para tornar a IA livre de preconceito e benéfica para todos é essencial que as pessoas que trabalham em IA reflitam a diversidade do mundo em que vivemos. Em um campo que tradicionalmente tem sido dominado por desenvolvedores brancos do sexo masculino, devemos fazer todos os esforços possíveis para promover uma cultura mais inclusiva. Na Philips, intensificamos recentemente nossos compromissos com a diversidade de gênero em cargos de diretoria, e dentro do mesmo espírito, a inclusão e a diversidade (seja de gênero, etnia ou formação profissional) serão prioritárias para nós à medida que continuamos a expandir nossas capacidades em IA e ciência de dados. Igualmente importante é que estamos promovendo uma intensa colaboração entre desenvolvedores de IA e especialistas clínicos para combinar os recursos de IA a uma compreensão contextual profunda do atendimento médico. Por exemplo, sempre que existirem diferenças conhecidas na manifestação de uma doença entre homens e mulheres ou entre diferentes grupos étnicos, os médicos podem ajudar a validar as recomendações algorítmicas de modo a garantir que não estejam prejudicando grupos específicos inadvertidamente. Para complementar ainda mais esse conhecimento especializado, estatísticos e metodologistas com um profundo conhecimento do preconceito e de estratégias de mitigação apropriadas são outro ativo vital para as equipes de desenvolvimento de IA. Somente através de uma verdadeira cooperação multidisciplinar poderemos tirar proveito mútuo de nossos pontos fortes e compensar os pontos cegos de cada um.

2. Diversidade de dados A disponibilidade limitada de dados (de alta qualidade) pode ser um obstáculo significativo ao desenvolvimento de uma IA que represente com precisão a população visada. Para promover o desenvolvimento de uma IA justa e livre de preconceitos, devemos buscar agregar conjuntos de dados mais amplos, com abundância de anotações e coletados nas diversas instituições — de uma forma segura e protegida que preserve a privacidade do paciente. Por exemplo, o Instituto Philips de Pesquisas de e-UTI foi criado como uma plataforma para promover o conhecimento sobre cuidados críticos, reunindo dados anonimizados de mais de 400 UTIs participantes nos EUA. O repositório de dados tem sido usado para desenvolver ferramentas de IA para cuidados críticos, incluindo um algoritmo que ajuda a decidir se um paciente está pronto para receber alta da UTI. No contexto da COVID-19, os pesquisadores também solicitaram um compartilhamento mais amplo dos dados de pacientes entre instituições e até entre países para garantir que os algoritmos de apoio a decisões clínicas sejam desenvolvidos a partir de conjuntos de dados diversificados e representativos, ao invés de amostras limitadas convenientes de centros médicos acadêmicos [8]. 3. Diversidade de validação Após ter sido desenvolvido, um algoritmo requer uma validação minuciosa para garantir que funcione com precisão em toda a população visada, não apenas em um subconjunto dessa população. Os algoritmos podem precisar ser retreinados e recalibrados quando forem aplicados a pacientes de diferentes países ou etnias, ou mesmo quando forem usados em hospitais diferentes no mesmo país. É encorajador o fato de termos observado em nossa própria pesquisa, baseada no repositório de dados de e-UTIs, que os algoritmos derivados de dados provenientes de diversos hospitais tendem a se generalizar o suficiente para manterem sua eficácia em outros hospitais dos EUA não incluídos no conjunto de dados original. Mas um escrutínio cuidadoso é sempre necessário. Por exemplo, quando testamos na China e na Índia alguns de nossos algoritmos de pesquisa de e-UTIs desenvolvidos nos EUA , descobrimos que o retreinamento local era necessário. Devido ao fato de que o risco de preconceito precisa ser cuidadosamente controlado, também precisamos ter salvaguardas sólidas em torno do uso de IA programada para o autoaprendizado. Um algoritmo pode ser cuidadosamente validado para o uso pretendido antes de sua introdução no mercado, mas o que acontecerá se continuar a aprender com novos dados nos hospitais onde for implementado? Como podemos garantir que esse preconceito não irá se infiltrar inadvertidamente? Como os reguladores também reconheceram, um monitoramento contínuo será necessário para garantir um desempenho justo e livre de preconceitos.
Um futuro mais justo para todos
Ainda há muito trabalho a ser feito, mas acredito que, com uma diversidade adequada de pessoas, dados e validação, corroborada por sólidos sistemas de gestão de qualidade e processos de monitoramento, poderemos mitigar com sucesso o risco de preconceito em IA. Melhor ainda, poderíamos tornar o atendimento médico mais igualitário ao adaptarmos os algoritmos para populações específicas de pacientes, incluindo grupos historicamente desfavorecidos ou sub-representados?
Poderíamos tornar o atendimento médico mais igualitário ao adaptarmos os algoritmos para populações específicas de pacientes, incluindo grupos historicamente desfavorecidos ou sub-representados?
Por exemplo, sabendo que a doença cardíaca coronariana tem sido tradicionalmente subpesquisada, subdiagnosticada e subtratada em mulheres [11], poderíamos desenvolver algoritmos especificamente voltados a detectar ou prever as manifestações da doença em mulheres? Em nossa era de medicina de precisão, na qual estamos cada vez mais migrando do paradigma de um modelo único para uma abordagem personalizada no atendimento médico, trata-se de um caminho interessante para novas pesquisas — que, naturalmente, devem respeitar integralmente os limites éticos, legais e regulatórios em torno do uso de dados pessoais confidenciais. No futuro, posso imaginar que será possível sintonizar um algoritmo para uma população específica de pacientes visados, com vistas a um desempenho otimizado e sem preconceitos. Poderia ser mais um passo em direção a um futuro mais justo e inclusivo para o atendimento médico, facilitado por uma IA que não só reconheça a variação entre diferentes grupos de pacientes, mas seja projetada para capturá-la. Referências [1] Obermeyer, Z., Powers, B., Vogeli, C. e Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366: 447-45. https://doi.org/10.1126/science.aax2342 [2] HIMSS (2019), encomendada pela Philips. Artificial intelligence and machine learning in healthcare. Pesquisa realizada junto a 234 entrevistados em organizações do setor de atendimento médico nos EUA. [3] Goddard, K., Roudsari, A. e Wyatt, J. (2012). Automation bias: a systematic review of frequency, effect mediators, and mitigators. JAMIA, 19(1): 121-127. https://doi.org/10.1136/amiajnl-2011-000089 [4] Feldman, S., Ammar, W., Lo, K. et al. (2019). Quantifying sex bias in clinical studies at scale with automated data extraction. JAMA, 2(7): e196700. https://doi.org/10.1001/jamanetworkopen.2019.6700 [5] Redwood, S. e Gill, P.S. (2013). Under-representation of minority ethnic groups in research - call for action. Br J Gen Pract. 63(612): 342-343. https://doi.org/10.3399/bjgp13X668456 [6] Popejoy, A. e Fullerton, S. (2016). Genomics is failing on diversity. Nature, 538(7624): 161-164http://doi.org/10.1038/538161a [7] Adamson, A. e Smith, A. (2018). Machine learning and health care disparities in dermatology. JAMA Dermatology. 154(11): 1247–1248. https://doi.org/10.1001/jamadermatol.2018.2348 [8] Röösli, E., Rice, B. e Hernandez-Boussard, T. (2020). Bias at warp speed: how AI may contribute to the disparities gap in the time of COVID-19. JAMIA, ocaa210. https://doi.org/10.1093/jamia/ocaa210 [9] Cirillo, D., Catuara-Solarz, S., Morey, C. et al. (2020). Sex and gender differences and biases in artificial intelligence for biomedicine and healthcare. npj Digit. Med. 3: 81. https://doi.org/10.1038/s41746-020-0288-5 [10] Goulart, B., Silgard, E., Baik, C. et al. (2019). Validity of natural language processing for ascertainment of EGFR and ALK test results in SEER cases of Stage IV Non-Small-Cell Lung Cancer. Journal of Clinical Cancer Informatics. 3:1-15. https://doi.org/10.1200/CCI.18.00098 [11] Mikhail, G.W. (2005). Coronary heart disease in women. BMJ (Clinical research ed.), 331(7515): 467–468.https://doi.org/10.1136/bmj.331.7515.467 Notas [i] Com base em suas análises, mais tarde os pesquisadores passaram a trabalhar em conjunto com os desenvolvedores do algoritmo para reduzir o preconceito racial.
Share on social media
Topics
Author

Henk van Houten
Former Chief Technology Officer at Royal Philips from 2016 to 2022
Mais notícias relacionadas
-
![Philips anuncia André Duprat como novo Brazil Country Leader]()
Abril 16, 2025
-
![Philips publica seu Relatório Anual 2024]()
Fevereiro 21, 2025
-
![Resultados do quarto trimestre e anuais da Philips 2024]()
Fevereiro 19, 2025
-
![10 tendências de tecnologia de saúde para 2025]()
Fevereiro 12, 2025
-
![Philips anuncia nova liderança na América Latina]()
Fevereiro 10, 2025

